K-Nearest Neighbor (KNN)
02 November 2025
Apa Itu K-Nearest Neighbor (KNN)?
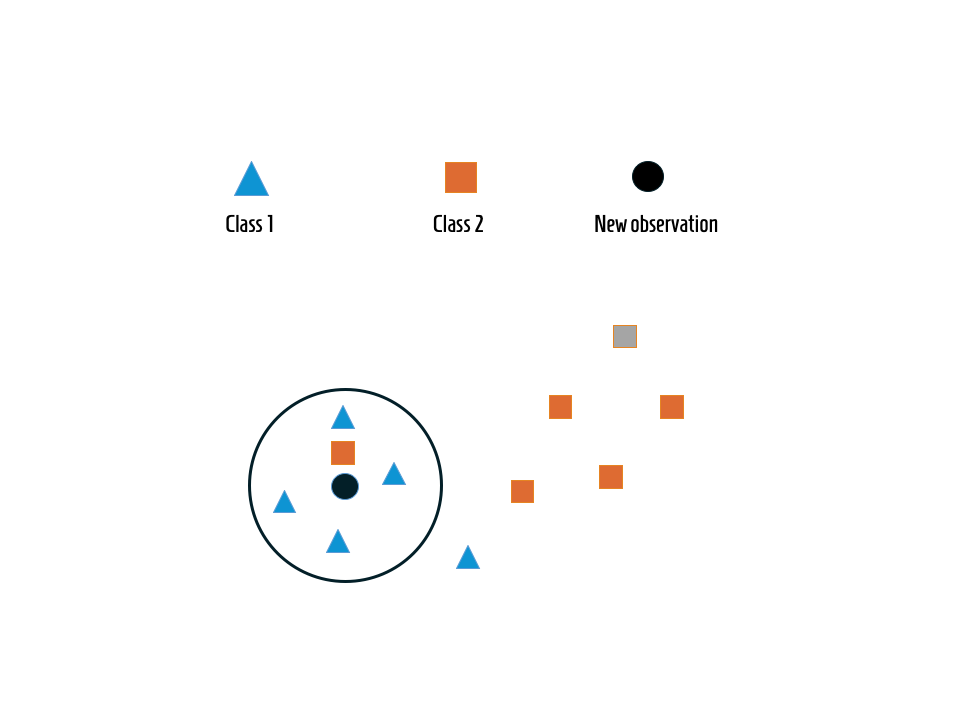
K-Nearest Neighbor atau KNN adalah sebuah algoritma yang sering digunakan dalam bidang machine learning untuk melakukan klasifikasi data. Algoritma ini bekerja dengan cara mencari sejumlah tetangga terdekat (k tetangga) dari data yang ingin diklasifikasikan, kemudian menentukan kelas data baru berdasarkan mayoritas kelas dari tetangga-tetangga tersebut. KNN termasuk dalam kelompok supervised learning, dimana proses klasifikasi dilakukan berdasarkan data pelatihan yang sudah diketahui kategorinya. Prinsip dasar KNN sangat sederhana, yaitu: mencari jarak antara data yang ingin diprediksi dengan data pelatihan lain, menentukan k tetangga terdekat, lalu mengklasifikasikan data baru berdasarkan kelas terbanyak dari tetangga tersebut.
Sejarah dan Penemu KNN
KNN pertama kali diperkenalkan pada tahun 1951 oleh Evelyn Fix dan Joseph Hodges dalam laporan teknis mereka yang berjudul "Discriminatory Analysis, Nonparametric Discrimination: Consistency Properties." Algoritma ini kemudian dikembangkan dan populer dalam berbagai aplikasi klasifikasi data. Inti dari KNN sudah digunakan sejak pertengahan abad 20 dalam statistika dan pola pengenalan, dan seiring dengan perkembangan komputer dan data science, KNN menjadi metode yang sangat populer karena kesederhanaannya dan efektivitasnya dalam banyak kasus.
Rumus KNN dan Cara Menghitung Jarak
Untuk menentukan siapa tetangga terdekat yang paling dekat secara matematis, kita menghitung jarak antara data baru dengan data-data pelatihan. Ada beberapa metode perhitungan jarak yang umum digunakan dalam KNN:
1. Jarak Euclidean
Jarak Euclidean adalah jarak garis lurus antar dua titik dalam ruang multidimensi. Rumusnya:
Dimana:
p dan q adalah dua titik data
n adalah jumlah dimensi fitur
2. Jarak Manhattan
Jarak Manhattan adalah jumlah nilai absolut dari selisih koordinat antara dua titik:
Jarak ini sering juga disebut jarak taksi atau jarak blok kota karena ilustasinya menyerupai rute jalan kota berbentuk grid.
Langkah-Langkah Algoritma KNN
Tentukan nilai kk, yaitu berapa banyak tetangga terdekat yang akan diperhitungkan (biasanya angka ganjil seperti 3, 5, atau 7).
Hitung jarak antara titik data baru dengan semua titik data pada data pelatihan.
Urutkan jarak tersebut dari yang terdekat sampai yang terjauh.
Ambil kk tetangga terdekat tersebut dan lihat kelasnya.
Tentukan kelas mayoritas dari tetangga tersebut, kelas ini menjadi hasil prediksi untuk data baru.
Contoh Kasus dan Perhitungan Manual KNN
Misalkan ada data pelatihan dengan dua fitur (dimensi) yaitu: tinggi badan (cm) dan berat badan (kg), dan kelasnya adalah "Sehat" atau "Tidak Sehat":
No Tinggi (cm) Berat (kg) Kelas 1 160 55 Sehat 2 165 60 Sehat 3 170 65 Tidak Sehat 4 175 70 Tidak Sehat Kita ingin mengklasifikasikan data baru dengan tinggi 168 cm dan berat 62 kg menggunakan k=3k=3.
Langkah 1: Hitung jarak Euclidean ke semua data pelatihan
Jarak ke data 1:
Jarak ke data 2:
Jarak ke data 3:
Jarak ke data 4:
Langkah 2: Urutkan jarak dari yang terkecil
Data 2: 3.61 (Sehat)
Data 3: 3.61 (Tidak Sehat)
Data 1: 10.63 (Sehat)
Data 4: 10.63 (Tidak Sehat)
Langkah 3: Ambil k=3k=3 tetangga terdekat
Data 2 (Sehat), Data 3 (Tidak Sehat), Data 1 (Sehat)
Langkah 4: Tentukan mayoritas kelas
Dari 3 tetangga, 2 adalah "Sehat" dan 1 "Tidak Sehat". Jadi data baru diklasifikasikan sebagai "Sehat".
Kesimpulan
KNN adalah algoritma yang mudah dipahami dan diterapkan untuk klasifikasi. Dengan tambahan pemilihan nilai kk yang tepat dan pengukuran jarak yang sesuai, KNN dapat memberikan hasil klasifikasi yang akurat di berbagai bidang, mulai dari pengenalan pola hingga sistem rekomendasi.
Referensi
K-Nearest Neighbor Algorithm Overview, Han (2006), Rizal (2013)
Penerapan K-Nearest Neighbor dan perhitungan manual, jurnal STMIK Dian Cipta Cendikia Kota Bumi, 2022
IBM explainers on KNN and distance metrics
Makalah original Evelyn Fix dan Joseph Hodges (1951)